Introduction
This summer, I created a machine learning model to predict fantasy football points (PPR Format) for the 2021-2022 NFL Season. I scraped data from pro-football-reference.com and implemented this data into a multiple-regression machine learning model, which could then be used to predict a given players statistics. My complete findings and source code can be found on my GitHub profile.
Project Outline
Both, Derrick Henry and Stefon Diggs are example of elite players in fantasy football. However, they could both get similar points in a game with extremely different statistics since they play different positions. Because of this, it was important to use several positional machine learning models, instead of one main model. As a result, different predictors were used depending on the position. I first used BeautifulSoup to scrape pro-football-reference.com for fantasy football stats from 2000 to 2016 and 2017 to 2020 to train my model. I also scraped data from 2016 to 2017 to test my models.
For quarterbacks, the following statistics were used to predict player performance: passing attempts per game, passing yards per game, rushing attempts per game, yards per attempt, rushing yards per game, rushing touchdowns per game, touchdowns per game, points per game (PPR), and value-based drafting (will be explained later). For running backs, the following statistics were used to predict player performance: age, rushing attempts per game, yards per attempt, rushing yards per game, rushing touchdowns per game, receptions per game, receiving yards per game, yards per reception, receiving touchdowns per game, touchdowns per game, points per game (PPR), and VBD. Lastly, for wide receivers and tight ends, the following statistics were used to predict player performance: receptions per game, receiving yards per game, yards per reception, receiving touchdowns per game, touchdowns per game, points per game (PPR), and VBD.
The program uses a Scikit learn linear regression model to predict the next year’s fantasy football points (per game in a PPR format). The code can be found in the “createModel.py” file on my GitHub. It takes the statistics listed in the previous paragraph as parameters to predict the next years PPG (PPR). Upon testing the model, the following data was collected. For quarterbacks, there was a median absolute error of 2.884 PPG. Running backs had a median absolute error of 2.092 PPG. Lastly, the wide receiver and tight end models had median absolute errors of 2.045 PPG and 1.542 PPG, respectfully. Additionally, it should be noted that the running back, wide receiver, and tight end models all had positive average and median errors, while the quarterback model did not. These errors were also much closer to zero than the absolute errors. In the future, I hope to increase the accuracy of these models, and I will go into further details on these plans in a later section. Lastly, I used R to create the graphs depicted in this article.
Results
The full results of this project can be found on my GitHub, and are located the file titled “predictedStats.csv”. Additionally, there are four files which contain the rankings and projections for players by position; these files include: “21QbStats.csv”, “21RbStats.csv”, “21WrStats.csv”, and “21TeStats.csv”. However, to summarize the data I have broken it down by position.
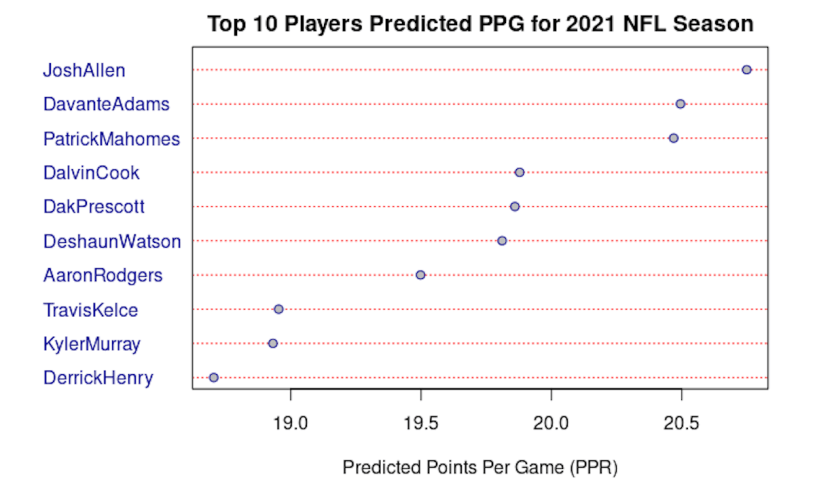
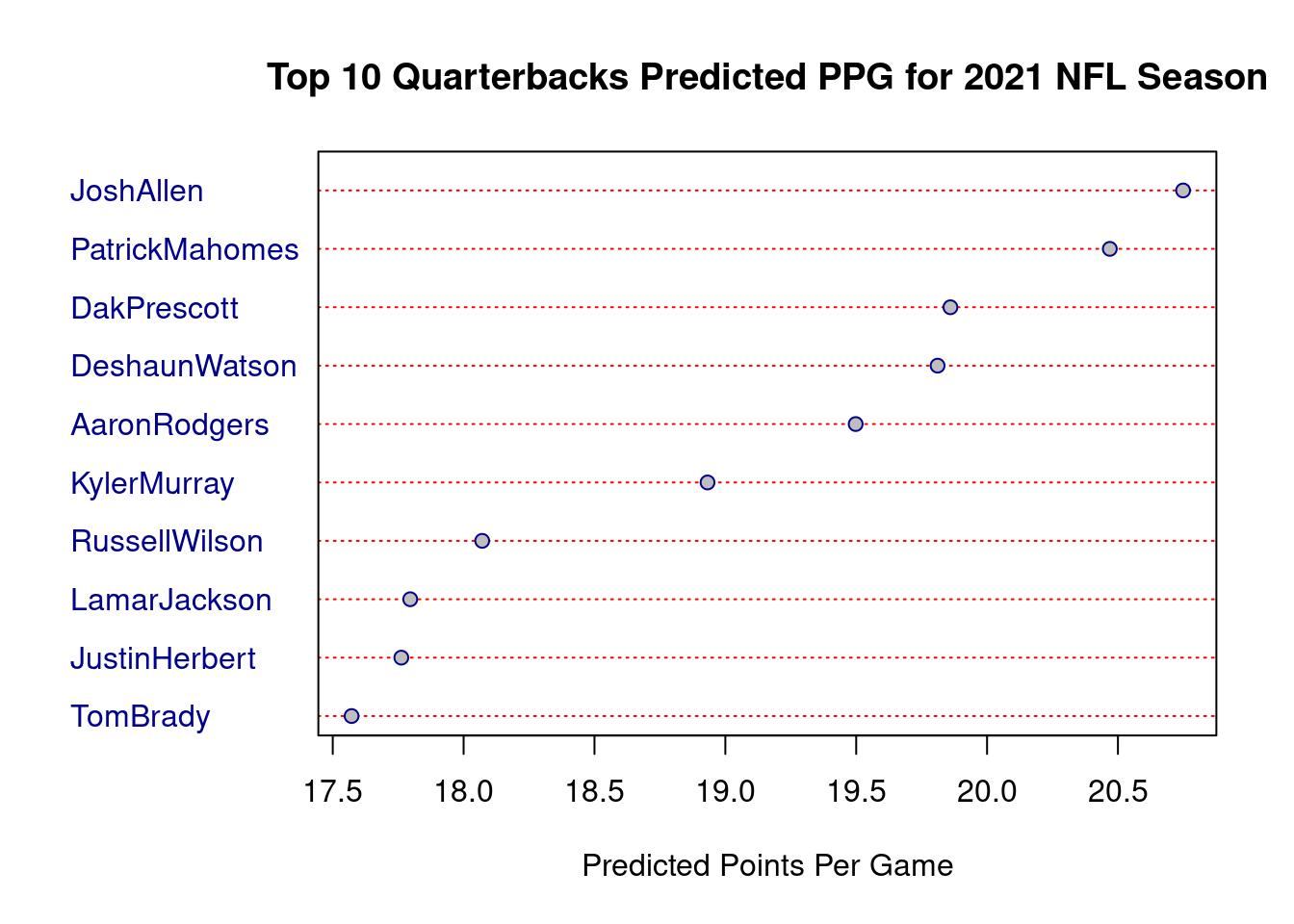
Starting with quarterbacks, a graph of the top 10 quarterbacks is shown below. During drafting season, Josh Allen was projected to have the best fantasy season with Patrick Mahomes not far behind. Some flaws in these rankings include Dak Prescott and Deshaun Watson. Prescott was likely overvalued by the program because his injury last year led to a vary small sample size which included very high statistics which would have been difficult to maintain throughout the entire season. Additionally, Deshaun Watson’s prediction was flawed since the program failed to account for his current legal situation. Marcus Mariota’s prediction was higher than it should have been and left him as the 11th ranked quarterback overall (not shown in graph) because of a small sample size last season where he started. The model also predicted Marcus Mariota to have a better season than he is currently having because it took the small sample size of when he was playing last year and did not account for the fact that Mariota is the backup in Las Vegas.
Next, we can look at running backs. This graph depicts the top 15 running backs for the 2021 season and shows that Dalvin Cook was the highest projected running back with Derrick Henry and Alvin Kamara slightly behind. Some flaws of these projections include Christian McCaffrey who was undervalued by the model during draft season as a result of his injuries from last season. Conversely, James Robinson was likely overvalued due to his current situation with Urban Meyer as head coach and the signing of Carlos Hyde for which the model did not take into consideration. Additionally, Ezekiel Elliott is having an improved season with Prescott back at quarterback, and Saquon Barkley is preforming better than expected (by the model) as his injury hurt his projection for the current season. Both of these players should have been drafted higher than the model suggested.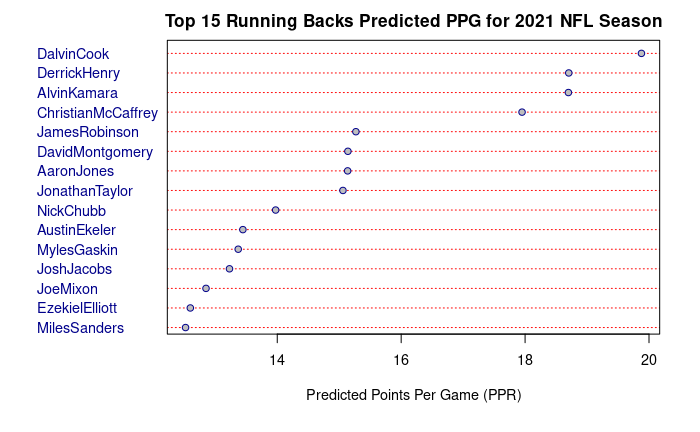
The next position is wide receiver, and a graph depicting the projected PPG of the top 15 wide receivers is shown below. Clearly, Davante Adams was projected to be the best wide receiver, but Tyreek Hill, Stefon Diggs, and Calvin Ridley were all projected exceptional seasons as well. Some potential oversights by this model include AJ Brown and Julio Jones whose statistics are affected by Jones’s move to Tennessee, but the model’s predictions did not reflect these circumstances. Additionally, Michael Thomas may have been undervalued during draft season as a result of his injuries last season.
Lastly, the final position to cover is tight ends. As shown in the graph below, Travis Kelce was clearly the highest projected tight end. However, Darren Waller and George Kittle were projected for elite seasons as well. After those three, there was a major fall-off between them and the next tight end. This will be discussed further in the next section, but because of this difference, this improves the value of having a top-tier tight end, and this value can be quantified by VBD.
Value-Based Drafting
Value-Based Drafting or VBD is a statistic that I mentioned earlier in the article, but I did not explain its meaning or significance. My calculations for this statistic are in the “useModel.py” file in the “useModel” function. It calculates the difference between the predicted PPR points (for the season) for a given player and the predicted PPR points (for the season) of the highest rated player (in the given position) left on the waiver wire. This stat reflects the importance of having elite running backs and tight ends. These two positions have steep drop-offs between the top players and the players left on waivers. For example, Travis Kelce is the highest projected TE and has a VBD of 201.79, while Josh Allen is the highest projected QB and only has a VBD of 119.17. This explains why Travis Kelce had an ADP of 7 in full PPR leagues (according to “fantasypros.com”), and why Josh Allen had an ADP of 26 (according to “fantasypros.com”) despite both players having been the highest rated players (according to my model) at their given positions.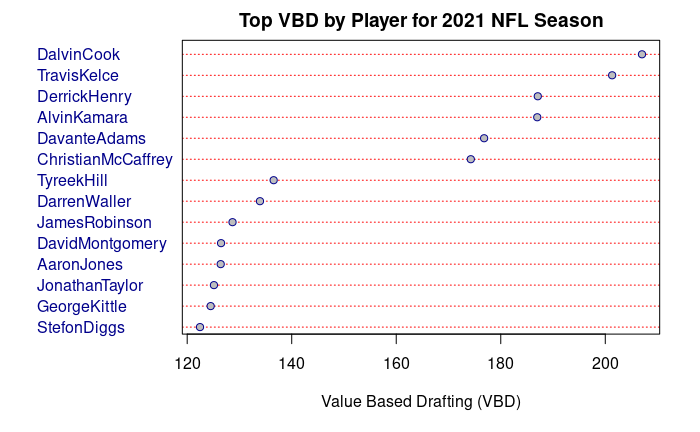
Future Improvements
For next season, I do have several potential improvements in mind. One possibility includes making predictions for the stats of each team, and then predicting what share of that a given player may gain. This should help account for roster changes between seasons. I also hope to find a way to predict rookie statistics. I have also been contemplating creating a feature which allows the model to update more frequently to update for changing scenarios and make predictions on a weekly basis in addition to seasonally. I also need to ensure that I am using up to date rosters, as retired players were included in this year’s model. I hope to improve my model so that it can go back multiple years and use that data to predict future stats. Players like Christian McCaffrey and Saquon Barkley were negatively impacted by model since they missed so much of the season last year. The last and likely most ambitious improvement that I would like to make would be a graphical user interface that could run the program and allow the user to filter and sort the data.
Conclusion
For its first year, this model is a good start. Machine Learning is constantly helping businesses and sports teams alike improve, and there is no reason why it cannot have an equally beneficial effect upon Fantasy Football. There are several improvements that I intend to make for next year, and I would appreciate any feedback. If you would like to see the source code and the full results, they are available on my GitHub.
